Home
About
Portfolio
Blog
Contact
Archive: AI
Latest Posts
12 December 2025
Running GPU-Accelerated LLMs on Proxmox with LXC
Read More
22 July 2023
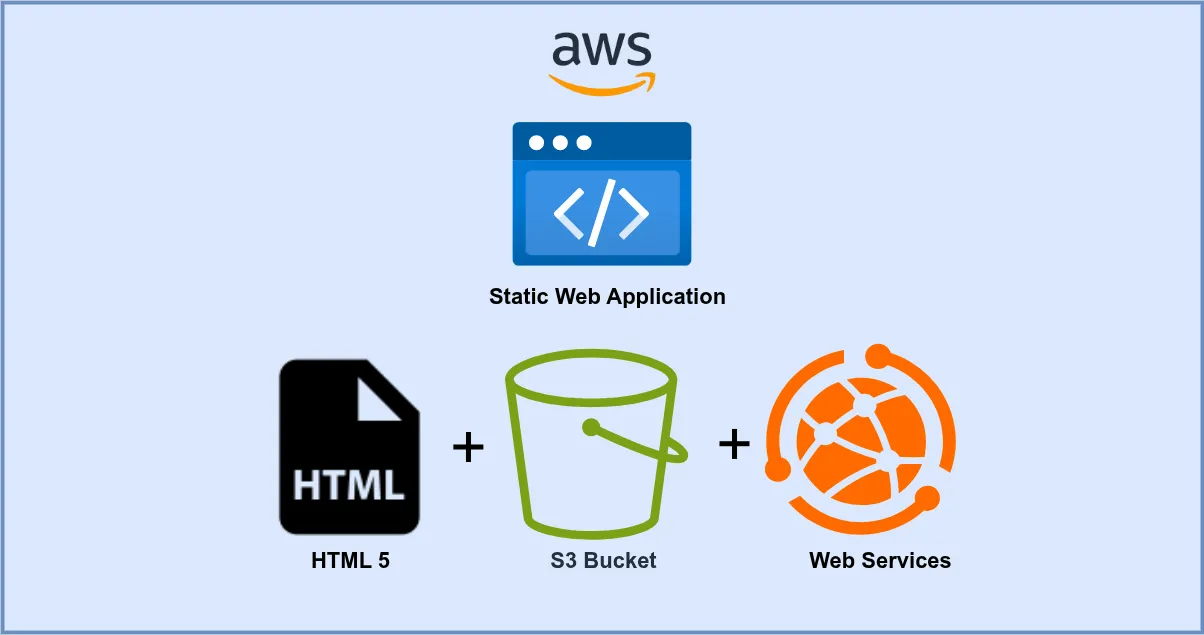
AWS Static Web Application Hosting - Part 2
Read More
20 June 2023
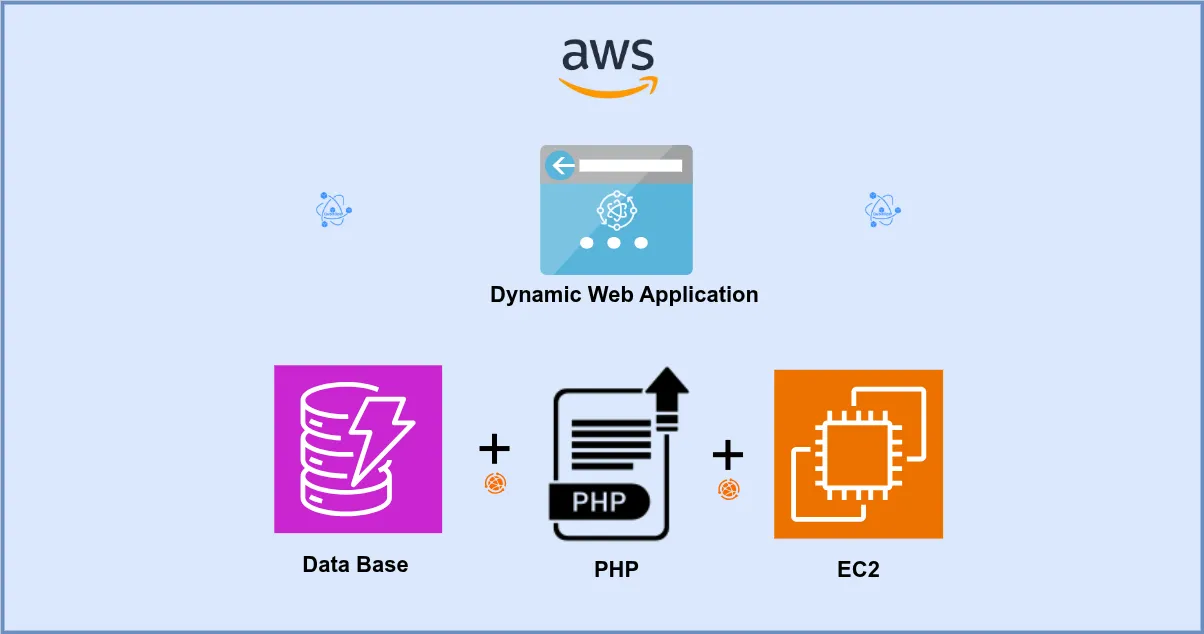
Ecommerce Web Application Hosting on AWS
Read More
24 February 2016
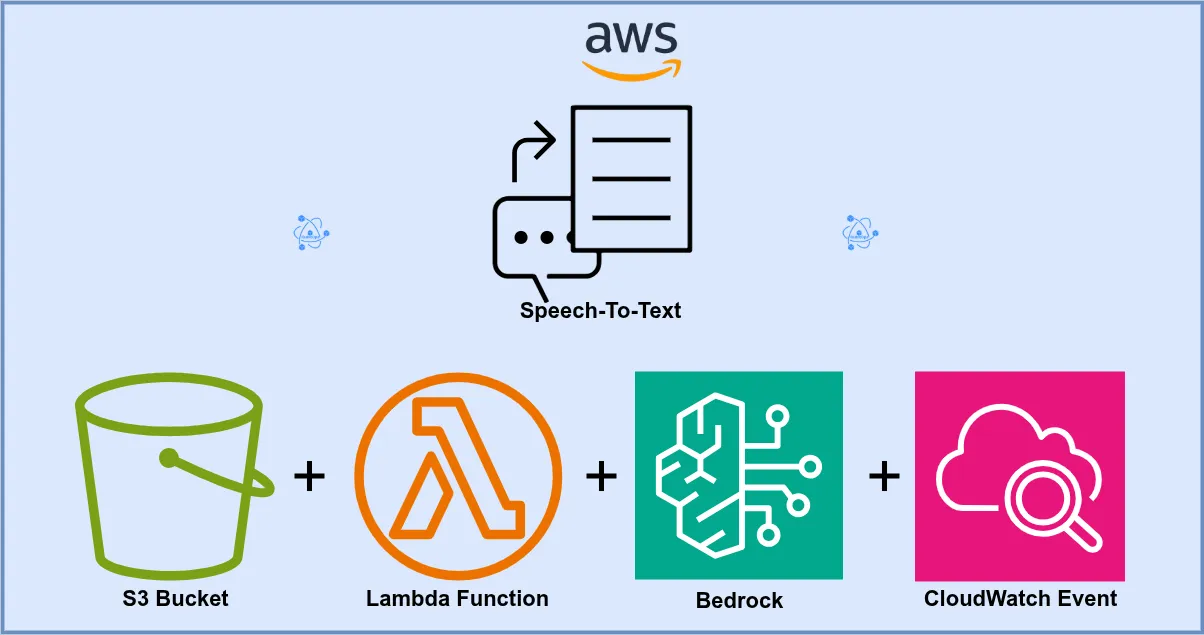
Scalable Serverless Speech-to-Text
Read More