Build a scalable serverless pipeline using AWS and Generative AI to transcribe speech, process text, and generate summaries for modern applications.
Introduction
Speech-to-text technology is a cornerstone for modern applications in education, healthcare, and media. By combining AWS serverless services and Generative AI, we’ve created a scalable pipeline that transcribes audio, processes the text, and generates concise summaries. This technical write-up explores the step-by-step architecture, implementation, and benefits of this solution.
Architecture Overview
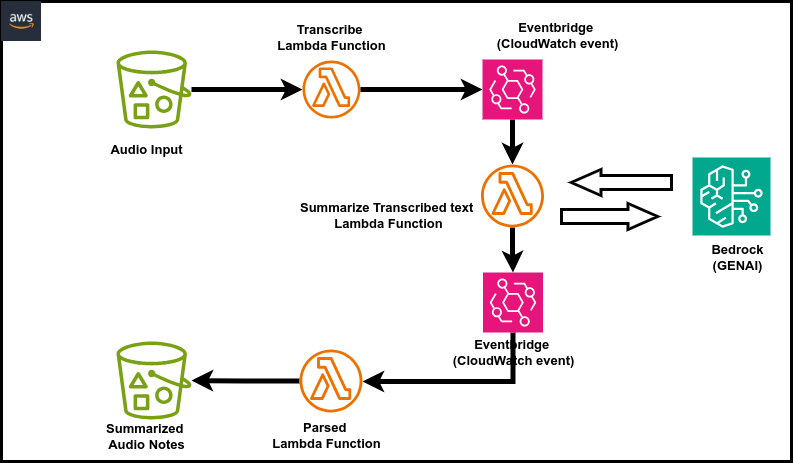
This serverless pipeline uses AWS services to handle the entire workflow:
- Audio File Upload: Users upload audio files to an S3 bucket.
- Automatic Transcription: AWS Lambda triggers Amazon Transcribe to convert speech to text.
- Text Processing: A second Lambda function saves the transcription to S3.
- Summarization: A third Lambda function sends the transcription to a Generative AI model to generate a summary.
Diagram: Architecture Workflow
Step-by-Step Implementation
Prerequisites
- AWS Account with permissions to use S3, Lambda, Transcribe, and CloudWatch.
- OpenAI API Key for Generative AI summarization.
- AWS CLI installed and configured.
Create S3 Bucket Create a bucket with the following structure:
s3://your-bucket-name/
input/ # For audio uploads
output/ # For transcription files
summary/ # For summarized text
Enable event notifications for the input/ folder to trigger Lambda.
Lambda Functions
Lambda Function 1: Audio_Transcribe Purpose: Starts a transcription job when a new file is uploaded.
import boto3
import time
s3 = boto3.client('s3')
transcribe = boto3.client('transcribe')
def lambda_handler(event, context):
for record in event['Records']:
bucket = record['s3']['bucket']['name']
file_name = record['s3']['object']['key']
object_url = f"s3://{bucket}/{file_name}"
job_name = f"{file_name.replace('/', '')[:10]}-{int(time.time())}"
transcribe.start_transcription_job(
TranscriptionJobName=job_name,
LanguageCode='en-US',
MediaFormat=file_name.split('.')[-1],
Media={'MediaFileUri': object_url}
)
print(f"Transcription job started: {job_name}")
- Trigger: S3 event for
input/folder. - Environment Variables: None required.
Lambda Function 2: Parse_Transcription Purpose: Retrieves and processes transcription results.
import boto3
import urllib.request
import json
s3 = boto3.resource('s3')
transcribe = boto3.client('transcribe')
BUCKET_NAME = 'your-bucket-name'
def lambda_handler(event, context):
job_name = event['detail']['TranscriptionJobName']
job = transcribe.get_transcription_job(TranscriptionJobName=job_name)
uri = job['TranscriptionJob']['Transcript']['TranscriptFileUri']
content = urllib.request.urlopen(uri).read().decode('utf-8')
transcription = json.loads(content)['results']['transcripts'][0]['transcript']
s3.Object(BUCKET_NAME, f"output/{job_name}_transcription.txt").put(Body=transcription)
print(f"Transcription saved to s3://{BUCKET_NAME}/output/{job_name}_transcription.txt")
- Trigger: CloudWatch Event for Transcribe job completion.
- Environment Variables:
BUCKET_NAME: Name of the S3 bucket.
Lambda Function 3: Summarize_Text Purpose: Generates a summary of the transcription using Generative AI.
import boto3
import openai
s3 = boto3.client('s3')
OPENAI_API_KEY = 'your-openai-api-key'
BUCKET_NAME = 'your-bucket-name'
def lambda_handler(event, context):
openai.api_key = OPENAI_API_KEY
### hgaskjdfjkngkjdnagakjdn
for record in event['Records']:
bucket = record['s3']['bucket']['name']
file_key = record['s3']['object']['key']
response = s3.get_object(Bucket=bucket, Key=file_key)
transcription = response['Body'].read().decode('utf-8')
completion = openai.Completion.create(
engine="text-davinci-003",
prompt=f"Summarize the following text:\n\n{transcription}",
max_tokens=200
)
summary = completion.choices[0].text.strip()
summary_key = file_key.replace("output/", "summary/").replace("_transcription.txt", "_summary.txt")
s3.put_object(Bucket=BUCKET_NAME, Key=summary_key, Body=summary)
print(f"Summary saved to s3://{BUCKET_NAME}/{summary_key}")
- Trigger: S3 event for
output/folder. - Environment Variables:
OPENAI_API_KEY: API key for OpenAI.BUCKET_NAME: Name of the S3 bucket.
Configure CloudWatch Set up CloudWatch Event rules:
- Trigger
Parse_Transcriptionwhen a Transcribe job completes. - Trigger
Summarize_Textwhen a transcription file is saved in theoutput/folder.
Testing the Solution
- Upload a Test File: Upload an audio file (e.g.,
.mp3) to theinput/folder. - Monitor Execution: Check CloudWatch logs for all three Lambda functions.
- Verify Outputs:
- Transcription saved in
output/. - Summary saved in
summary/.
- Transcription saved in
Benefits of the Architecture
- Scalability: Automatically handles multiple uploads concurrently.
- Cost-Efficiency: Serverless model ensures you pay only for what you use.
- Privacy: Audio and text remain within your AWS environment.
- Customizability: Extend the workflow with additional processing, such as sentiment analysis or language translation.
Conclusion
This serverless speech-to-text pipeline with summarization showcases the power of AWS and Generative AI. It’s scalable, cost-efficient, and flexible, making it an ideal solution for businesses looking to streamline audio processing workflows. Try implementing this project in your environment and take your data processing capabilities to the next level!
Let me know how it works for you or if you have any questions in the comments below!